Visual Analytics of Natural Language and Linguistic Data
Im Rahmen einer interdisziplinären Initiative entwickeln Informatiker und Linguisten an der Universität Konstanz gemeinsam neuartige Wege zur visuellen Analyse natürlicher Sprache für linguistische Untersuchungen. Die untersuchten Forschungsfragen stammen vor allem aus den linguistischen Bereichen der Typologie und der Historischen Linguistik. Der Schwerpunkt liegt auf der Untersuchung von Sprachmerkmalen und -phänomenen sowohl aus sprachübergreifender als auch aus diachroner Perspektive. Derzeit wird an drei Hauptbereichen gearbeitet, die im Folgenden kurz beschrieben werden.
Sprachübergreifender Vergleich von Sprachmerkmalen
Der Vergleich von Sprachmerkmalen zwischen verschiedenen heute gesprochenen Sprachen ist entscheidend, um mehr über Ursachen und Wirkungen von Sprachwandel zu erfahren. Er kann dazu beitragen, natürliche Sprache besser zu verstehen, und aufzeigen, welche Arten von Phänomenen allen Sprachen gemeinsam sind. Solche Phänomene können als historisch ziemlich stabil und damit als universell angesehen werden. Andere Phänomene können dagegen stark zwischen Sprachen variieren, was darauf hindeutet, dass sie wandelanfällig sind. Leider sind die verfügbaren Informationen für viele Sprachphänomene spärlich und ungenau, d. h. sie entsprechen einer groben, manuell konstruierten Kategorisierung, die nur für einen Teil der etwa 6.900 Sprachen der Welt verfügbar ist. Es gibt jedoch Fälle, in denen diese Lücke in Genauigkeit und Umfang mithilfe rechnerischer Mittel geschlossen werden kann. Bestimmte Sprachphänomene können approximiert werden, indem numerische Merkmale aus Texten abgeleitet werden. Diese Merkmale können in recht komplexen Beziehungsgefügen bestehen, weshalb geeignete Visualisierungen erforderlich sind, um sie dem Analysten zu vermitteln. Ein Beispiel für Sprachmerkmale sind Vokalverteilungen innerhalb von Wörtern, die anzeigen, ob eine Sprache Vokalharmonie aufweist oder Silbenreduplikation verwendet.

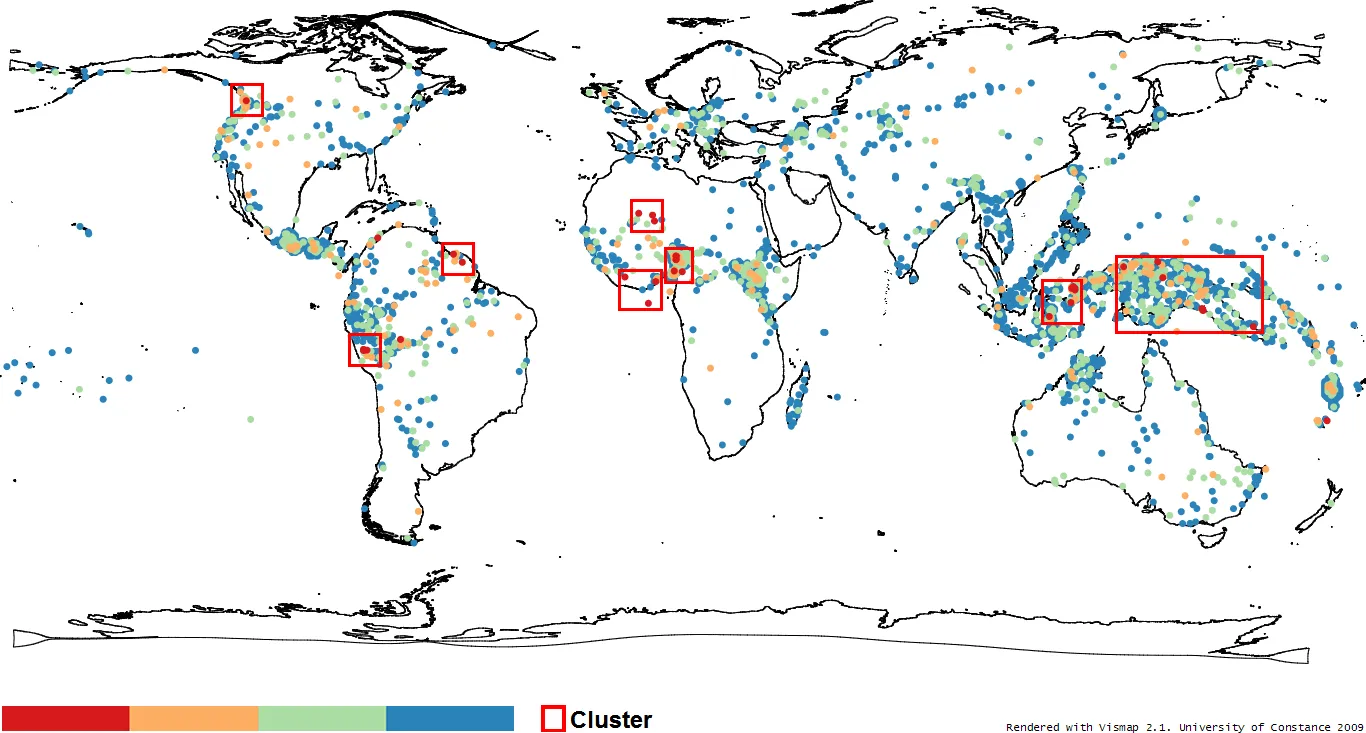
Analyse geografischer und genealogischer Verteilungen von Sprachmerkmalen
Beim Vergleich von Merkmalen zwischen Sprachen ist es von besonderem Interesse, die geografischen und genealogischen Implikationen zu untersuchen. Es kann sein, dass nur genetisch verwandte Sprachen oder Sprachen einer bestimmten Weltregion eine gewisse Besonderheit eines Merkmals teilen. Solche Erkenntnisse helfen bei der Hypothesenbildung, ob ein bestimmtes Merkmal eher durch Sprachkontakt beeinflusst oder unverändert aus Protosprachen ererbt sein dürfte. Ein vorläufiges Beispiel für die Darstellung der geografischen Verteilung eines Sprachmerkmals mittels einer verzerrten Weltkarte zeigt Abbildung 2.
Für weitere Details verweisen wir Sie auf das entsprechende Paper.
Diachrone Analyse lexikalisch-semantischen Wandels
Es wurde gezeigt, dass sich verschiedene Bedeutungen eines Wortes durch ihren Kontext disambiguieren und sogar induzieren lassen. In diesem Projekt zielen wir darauf ab, Visual-Analytics-Ansätze zu entwickeln, die die Entwicklung von Wortbedeutungen über die Zeit verfolgen. Ziel ist es, ein tieferes Verständnis dafür zu gewinnen, wie lexikalisch-semantischer Wandel geschieht. Abbildung 3 zeigt die quantitative Entwicklung verschiedener automatisch erlernter Bedeutungen für die Wörter „to browse” und „to surf” auf Grundlage täglicher Zeitungsausgaben über 20 Jahre.

Weitere Informationen zu dieser und verwandten Arbeiten finden sich in den folgenden Publikationen.